
Imagine a company launching a new AI chatbot last year. At first, everything looked perfect. The chatbot answered questions quickly, sounded confident, and impressed the team. But soon, users noticed something strange. Some answers looked correct but were actually wrong.
This problem happens because Large Language Models only know what they learned during training. They don’t always have access to the latest information. So when asked about something new, they often guess.
That’s where Retrieval Augmented Generation (RAG) changes the story. Instead of guessing, a RAG system first searches trusted sources – documents, databases, websites, or company knowledge bases. It uses that information to generate a response. The result is more accurate and reliable answers.
The demand for RAG is rising fast. According to Grand View Research, the global RAG market was valued at USD 1.2 billion in 2024 and is expected to reach nearly USD 11 billion by 2030. This shows how quickly organizations are adopting RAG to improve the quality of their AI systems.
For anyone who wants to build modern AI applications in 2026, learning RAG design patterns is no longer optional. It’s becoming a must‑have skill.

What is RAG Design Pattern & Why it Matters in 2026?
Think of a RAG design pattern as a clear recipe for building a Retrieval Augmented Generation system. It explains how information is searched, processed, checked, and finally passed to a large language model so that the answers are accurate and useful.
Different situations need different recipes. A customer support chatbot may follow one approach. A legal assistant may need another. A healthcare application might require something completely different.
Because every use case is unique, AI engineers in 2026 rely on different RAG patterns 2026 instead of sticking to a single method. This flexibility makes RAG systems stronger and more reliable across industries.
How a RAG Pipeline Actually Works: Step by Step
Understanding how RAG works is easier when you see it as a simple flow. Each step connects naturally to the next, turning a user’s question into a clear and accurate answer.
Step 1: A user asks a question.
Step 2: The system searches documents, databases, or knowledge sources to find relevant information.
Step 3: The most useful pieces of information are selected.
Step 4: That information is added to the prompt.
Step 5: The language model generates an answer using the retrieved context.
This sequence is called the RAG pipeline.
Modern organizations often improve this pipeline with extra layers. They add reranking systems to filter results more effectively, knowledge graphs to connect ideas, AI agents to make smart decisions, and validation steps to check quality. These upgrades make answers more accurate, reduce mistakes, and build trust in AI systems.
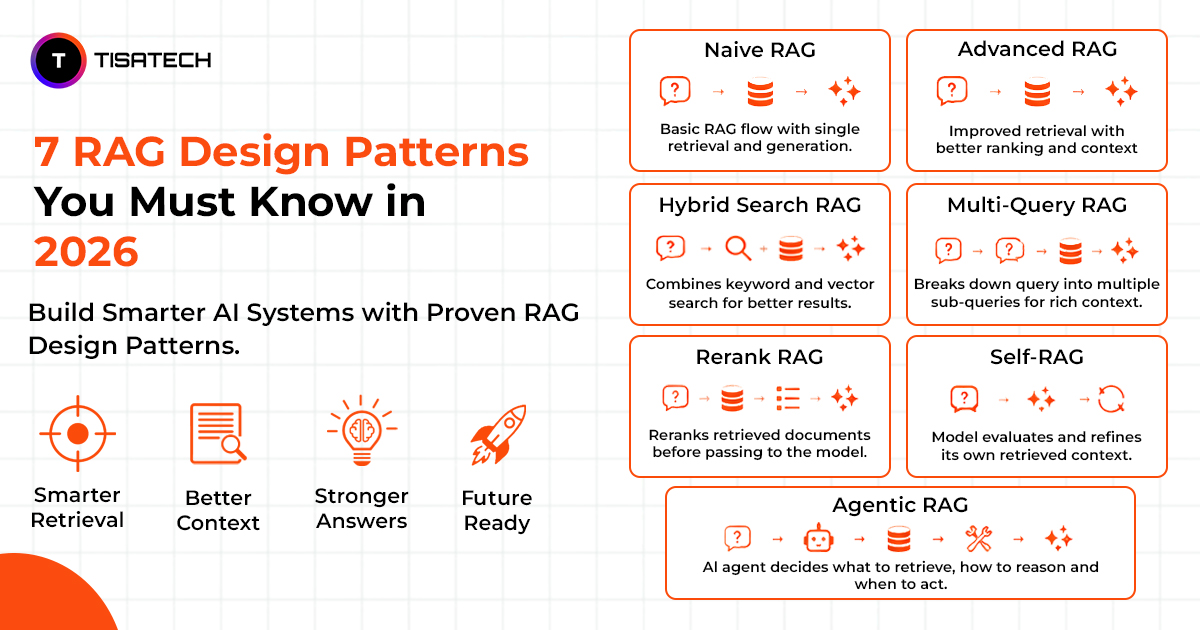
7 RAG Design Patterns Every AI Learner Must Know in 2026
Not every AI problem needs the same fix. As RAG systems have grown and matured, engineers have created different patterns to solve different challenges. Some patterns deal with noisy or irrelevant results, while others focus on reasoning across many documents. Together, these seven patterns cover everything from the basics to advanced methods used in real AI applications today.
Pattern 1: Naive RAG
Naive RAG is the starting point for building retrieval systems. In this approach, documents are split into chunks, converted into vectors, and stored in a vector database. When a user asks a question, the system retrieves the closest matching chunks and passes them to the language model.
This method is easy to set up and good for beginners, but it has clear limits. It often brings back noisy or irrelevant content and struggles with questions that need deeper reasoning. Naive RAG is fine to begin with, but it is not strong enough to rely on for advanced or production‑level applications.
Pattern 2: Retrieve and Rerank
This pattern is the most impactful upgrade from Naive RAG. Instead of sending a small set of chunks directly to the language model, it first collects a broader set and then filters them down to the best ones.
Step 1: The user asks a question.
Step 2: The system runs a vector search and retrieves around 50 chunks.
Step 3: A separate model called a cross‑encoder scores and reranks those chunks.
Step 4: Only the top 5 most relevant chunks are passed to the LLM.
Step 5: The LLM generates the final answer using this clean context.
Flow: Query → Vector Search (top 50) → Reranker (top 5) → LLM → Answer.
By filtering out noise, the reranker ensures the LLM gets only relevant context. This leads to faster responses, lower costs, and much better answers.
Pattern 3: Hybrid RAG
Vector search is great for finding meaning in text, but it can miss exact technical terms. Keyword search catches those exact words, but it often misses the bigger picture.
Hybrid RAG combines both. It runs vector search to capture meaning and keyword search (BM25) to catch exact terms. The results are merged using Reciprocal Rank Fusion, giving a balanced set of answers.
This mix makes Hybrid RAG a default choice in many production systems in 2026. It works especially well for enterprise setups that deal with both technical jargon and everyday language.
Pattern 4: Graph RAG
Regular vector search is good at finding similar text, but it doesn’t understand how pieces of information connect. For example, if a legal question needs data from 10 different documents, vector search just returns the closest chunks without linking them together.
GraphRAG fixes this by using a knowledge graph. It extracts key entities and maps their relationships. When a user asks something, the system walks through this graph to find connected information instead of just the nearest match.
Microsoft open‑sourced GraphRAG in July 2024, and it’s especially useful for legal compliance, research analysis, and cross‑document reasoning.
Pattern 5: Multimodal RAG
Early RAG systems only worked with plain text. But real world data isn’t just text – it includes charts, diagrams, PDFs, and infographics. Standard RAG misses all of that.
Multimodal RAG solves this by handling both text and visuals together. The model can “see” the retrieved visual context and answer directly from it. By 2026, this has become mainstream thanks to models like GPT‑4o and Gemini 2.0 Flash.
It’s especially useful for financial reports, enterprise slide decks, and technical documents with diagrams.
Pattern 6: Agentic RAG
In the earlier patterns, the system always retrieves something as soon as a user asks a question. But sometimes retrieval isn’t needed, or the query may require multiple smaller searches.
Agentic RAG solves this by putting an AI agent in charge. The agent first analyzes the query, then decides if retrieval is needed, which source to search, and how many times. This makes the process flexible and reasoning‑driven instead of a fixed pipeline.
Flow: Query → Agent Reasoning → Search Decision → Retrieve → Evaluate → Search Again if Needed → Answer
Agentic RAG is best for multi‑step reasoning and dynamic use cases where different questions need different retrieval strategies.
Pattern 7: Corrective RAG (CRAG)
Even strong retrieval systems make mistakes. Sometimes they bring back wrong or irrelevant content, and the LLM either refuses to answer or gives a wrong reply.
Corrective RAG fixes this with a feedback loop. After retrieval, it checks if the chunks are useful. If the score is low, it runs another search, maybe on the web or in a different database, before giving the answer.
A study from Carnegie Mellon in June 2026 showed that using corrective retrieval cut hallucination rates from 14.1% down to 4.9% on a large financial compliance dataset (source: aithinkerlab.com).
CRAG is best for finance, healthcare, and legal tech where wrong answers can be very costly.
Which RAG Design Pattern Should You Learn First?
If you’re new to RAG, don’t rush into all seven patterns at once. The smart way is to build your knowledge step by step, moving from the basics to the advanced.
Naive RAG → Start here. Learn chunking, embeddings, and vector search.
Retrieve and Rerank → First upgrade. Cleans noisy results and improves answer quality.
Hybrid RAG → Combine vector + keyword search for more reliable queries.
Agentic RAG → Adds reasoning. The agent decides when and how to retrieve.
Then move to specialized ones:
GraphRAG → For connected or relational data.
Multimodal RAG → For charts, images, and PDFs.
Corrective RAG → For high‑accuracy domains like finance, healthcare, and legal.
Learn Advanced AI at TISA-TECH, Jaipur
It’s good to learn AI concepts, but the real difference comes when you use them in projects. Employers today want people who can build solutions, solve problems, and apply modern AI in real work. Students planning a career in Artificial Intelligence can start with the List of AI Courses which gives a clear view of different domains and career paths.
TISA‑TECH, Jaipur helps students gain practical experience through project‑based learning. Training covers key areas like Large Language Models, RAG systems, AI agents, prompt engineering, and modern AI workflows. Instead of just theory, students get to work on projects and see how AI applications are built and used in real business environments.
The Govindpura training center provides an environment where students learn by building. Working on practical projects helps them understand how modern AI systems are designed, tested, and deployed. Those who want to strengthen their technical knowledge and gain hands-on experience with industry‑relevant projects can also explore Advanced AI Learning in Jaipur, where the focus is on practical implementation and real‑world AI development.
Conclusion
RAG is not just a big word. It is the system behind most serious AI products in 2026. If you want to grow in AI, learning these RAG patterns is now a must.
The best way to learn is to start small. Know why each pattern exists and what problem it solves. That clear understanding will help you more than just memorizing definitions.
Students in Jaipur who want proper guidance can join TISA‑TECH’s AI programs. The training is made for learners who want to go beyond theory, practice with real projects, and get ready for jobs in AI.
FAQs Section
Ans. They are different architectural approaches to building a retrieval augmented generation system. Each one solves a specific challenge like improving accuracy or reducing hallucinations.
Ans. Start with Naive RAG. Then move to Retrieve and Rerank as your first real improvement.
Ans. A normal LLM answers from its training data only. A RAG system retrieves fresh information from an external source at query time and uses it to generate a more accurate answer.
Ans. CRAG stands for Corrective RAG. It adds a self-correction loop so if retrieved content is not relevant, the system triggers a new search before generating any answer.
Ans. TISA-TECH offers structured AI training covering RAG architecture, LLM applications, and advanced AI engineering. Visit TISA-TECH’s AI course page to explore your options.

